生物信息常用文件格式(2)- FASTQ
FASTQ格式是一种保存生物序列(通常为核酸序列)及其测序质量得分信息的文本格式。
格式
FASTQ文件中,一条序列信息由四行组成。
- 第一行以@开头,之后为序列的标志符和描述信息;
- 第二行为序列信息;
- 第三行以+开头,后面可加上序列标志符,描述信息,也可以不加任何东西;
- 第四行为第二行每个碱基的质量得分,以单个ASCII字符表示;
一个FASTQ例子如下:
@SIM:1:FCX:1:15:6329:1045 1:N:0:2
TCGCACTCAACGCCCTGCATATGACAAGACAGAATC
+
<>;##=><9=AAAAAAAAAA9#:<#<;<<<????#=
对于第三行来说,一般的格式如下,后面还有可能会有barcode信息
@<instrument>:<run number>:<flowcell ID>:<lane>:<tile>:<x-pos>:<y-pos> <read>:<is filtered>:<control number>:<sample number>

测序质量
第四行保存了测序质量值,其主要通过以下方法进行计算:
假设测序质量错误率为P,则P取值越小越好,如果直接存储小数点,则会占用比较多的位置,所以人们对它进行了转换:
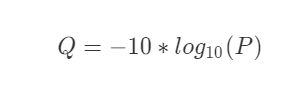
| P | Q |
| 0.1 | 10 |
| 0.01 | 20 |
| 0.001 | 30 |
| 0.0001 | 40 |
在上面的基础上,将Q值转为ASCII码,保存在FASTQ文件中。在转换为ASCII码的时候,由于前33个字符无法显示,所以一般会将Q值加上33或者加上64后再进行转换为ASCII码,即Phred33或者Phred64。目前基本上都是Phred33了。一般在实际工作中会把质量分数小于20的碱基认为是不可靠的,当这样的碱基占read的20%以上的话,即会考虑丢弃该条read。
参考:
https://help.basespace.illumina.com/articles/descriptive/fastq-files/
版权声明:本文转载请注明出处!



最新评论:
发表评论
电子邮件地址不会被公开。 必填项已用*标注